We identify and manipulate high-level cognitive representations within neural networks, enabling more precise control over model behavior than traditional fine-tuning approaches.
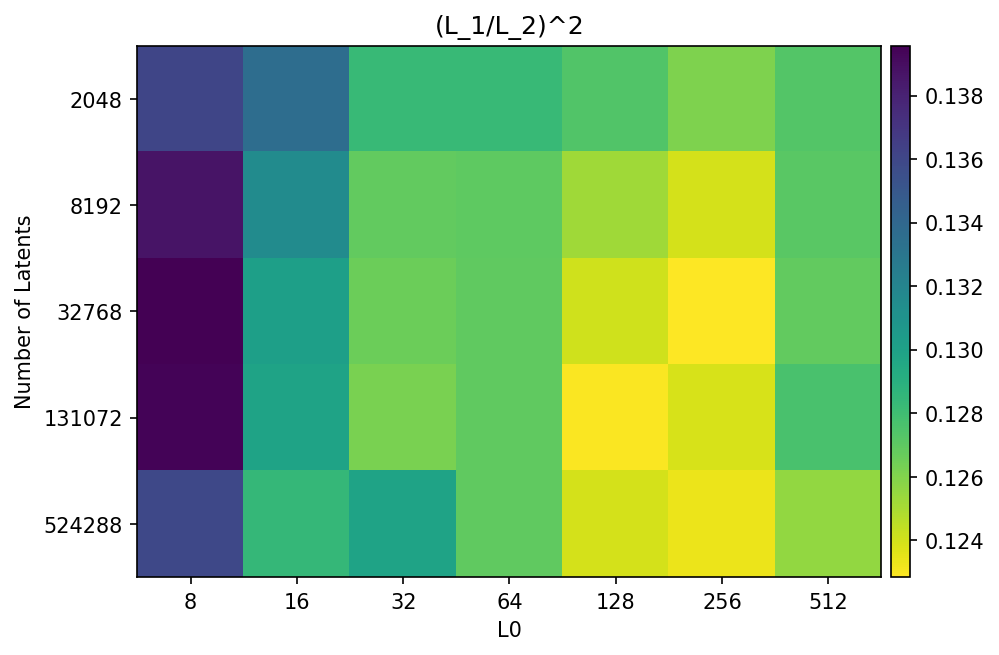
We apply dictionary learning at scale to extract millions of interpretable features from a production language model, finding features corresponding to a wide range of concepts.
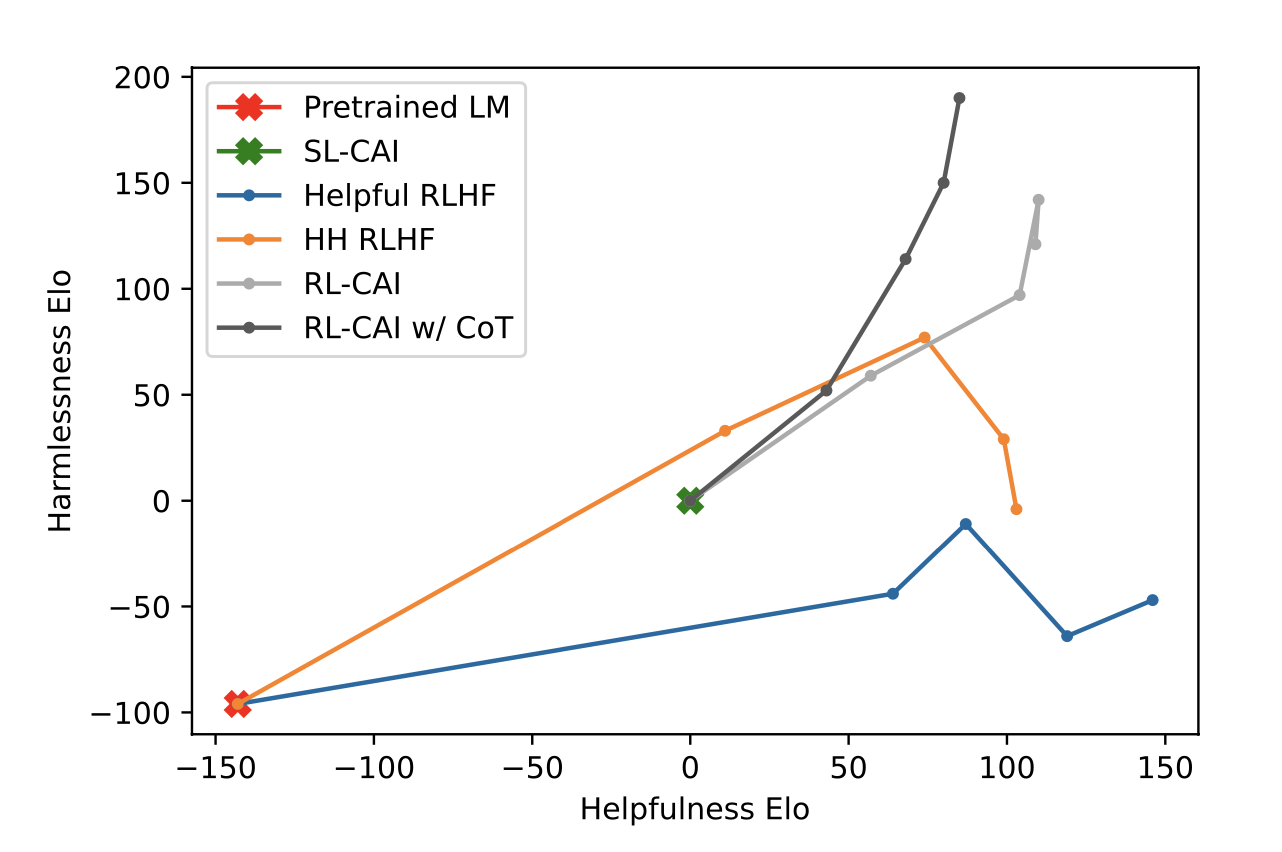
We propose Constitutional AI (CAI), a method for training AI systems that are helpful, harmless, and honest, using a set of principles to guide AI behavior without extensive human feedback on harms.

We find that current behavioral safety training techniques are insufficient to remove deceptive behavior from large language models, even when the deceptive behavior was inserted during pretraining.